

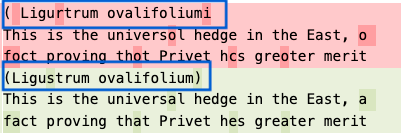
Optical character recognition (OCR) plays a critical part in BHL’s contributions to the scientific community. OCR in and of itself is a remarkable achievement, converting images of typewritten text to computer-readable text with “pretty good” accuracy. OCR on handwritten text is an even greater challenge to address and is beyond the scope of the improvements discussed here. The scientific work that BHL supports demands the best accuracy that we can provide using available tools, and let’s be honest, available budgets.
Recently, our colleagues at the Internet Archive made the transition away from the ABBYY FineReader OCR software to the Tesseract Open Source OCR engine. Over the past year or more, the OCR team at the Internet Archive has adapted and fine-tuned Tesseract to their workflows. Our first impression is that Tesseract OCR is more than “pretty good” in its ability to identify text from the page images provided to it.
The downside to this is that the Internet Archive has rightfully chosen to not re-process all existing text content through the Tesseract OCR engine. This is a prohibitively expensive and time-consuming prospect given that they have 35 million text-based items and reprocessing them would take several years and use up resources that could otherwise be used for gathering new content.
However, in the interests of supporting the efforts of the BHL community, the BHL Tech Team is working with our Internet Archive partner to reprocess some of BHL’s oldest content with the newest available version of Tesseract OCR. We are currently in a testing phase, and this blog post details some of our early results.




