

BHL Journal Articles Are Now Discoverable via Unpaywall
Earlier this week, Rod Page and I received an email from Richard Orr, the Lead Developer at Unpaywall, telling us that he had created a work-around that would finally enable the Unpaywall extension to discover content in BHL. And I (Nicole) literally spent the rest of the day jumping for joy.
Let us explain:
Firstly, what’s a DOI?
DOIs (Digital Object Identifiers) are used throughout the scholarly research community to uniquely identify academic articles. They help readers locate the definitive version of a published article, and they make linking together the academic literature much easier – look at any recent paper and you’ll see that most of the references cited have DOIs.
DOIs do two things: 1) they uniquely identify an article, and 2) they point to the online location of the definitive version of that article (typically hosted by the article’s publisher).
Many articles are not free to read: a significant proportion of both recently-published and historic articles are locked behind paywalls. However, with the rise of open access, it’s increasingly the case that there may be a free version of an article available somewhere online. BHL, for example, has scanned and made available tens of thousands of articles that also exist on commercial publishers’ websites. DOIs always direct users to the definitive version of an article. But if the definitive version is behind a paywall (as they so often are), how do we tell users that BHL has a free version available? Enter Unpaywall.
What’s Unpaywall?
Unpaywall finds (legally) open access versions of paywalled literature. Since its launch in 2016, Unpaywall has become an indispensable tool for scientists (see “How Unpaywall is transforming open science”). Unpaywall’s free browser extension (downloadable via their website) displays a discrete padlock symbol on the side of your browser whenever you are on a paywalled paper. If Unpaywall is able to locate a freely-accessible copy of the article elsewhere, the padlock symbol appears green and clicking on it will take you directly to the open access version. To discover whether an article is free, Unpaywall scans a database of millions of articles compiled from over 50,000 sources. Until this week, BHL wasn’t one of them.
Why couldn’t Unpaywall link to BHL?
BHL contains hundreds of thousands of journal articles. More than a quarter of a million of these articles have been indexed (the vast majority by Rod Page via Biostor), which means that they now have article-level landing pages containing their article-level metadata. Tens of thousands of these article landing pages now have DOIs. This should have made them discoverable, but Unpaywall still couldn’t find them.
In June, we contacted Unpaywall to find out why. It turns out that the reason BHL content has never been picked up by Unpaywall is because of the way BHL uploads and presents its journal content. Most providers of online journals present each article neatly packaged as an individual PDF. BHL, however, is first and foremost a virtual library. We upload complete volumes of journals made up of individual page images. Our article landing pages don’t link to PDFs; they link to the page in the volume upon which the article starts. Unpaywall looks for a PDF link to confirm that the document is actually available. Thus, the 57 million pages of open access content on BHL was excluded from Unpaywall’s database.
After we explained to Unpaywall how significant BHL’s content was, Richard Orr, Unpaywall’s Lead Developer, very kindly agreed to create a work-around, specifically for BHL, that would enable Unpaywall to link to BHL article landing pages. The result of this work-around is that (as of this week) 43,000 journal articles on the BHL website are now discoverable via Unpaywall.
To demonstrate how useful this is, here are two examples:
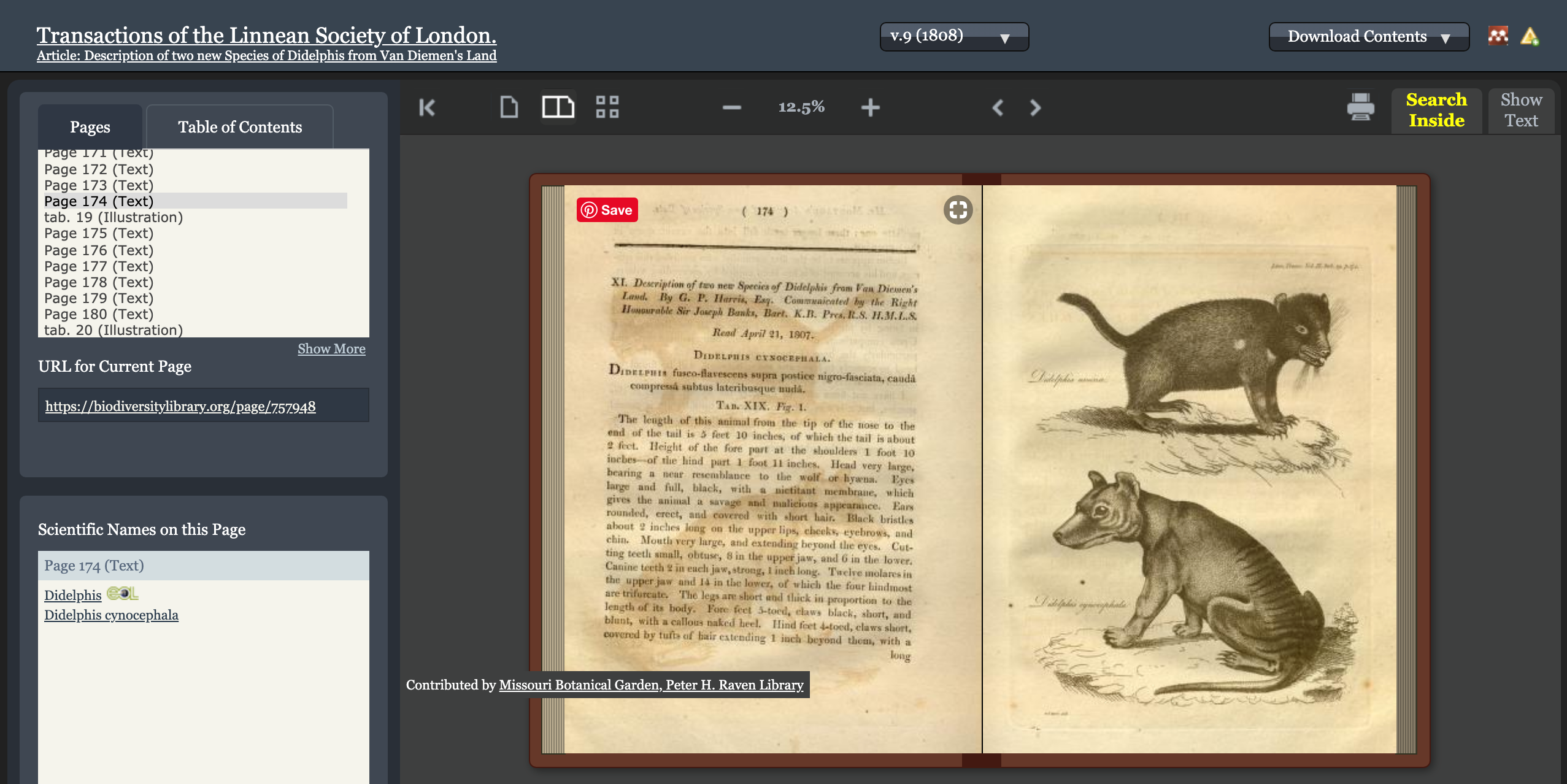
The first description of the iconic (sadly now-extinct) Thylacine (or Tasmanian Tiger) was published in the Transactions of the Linnean Society of London in 1808. This article is well and truly out of copyright and yet the definitive version of this article is behind a paywall on the Wiley Online website: https://doi.org/10.1111/j.1096-3642.1818.tb00336.x. Downloading the PDF of this out-of-copyright article from the Wiley website will cost you $42 USD.
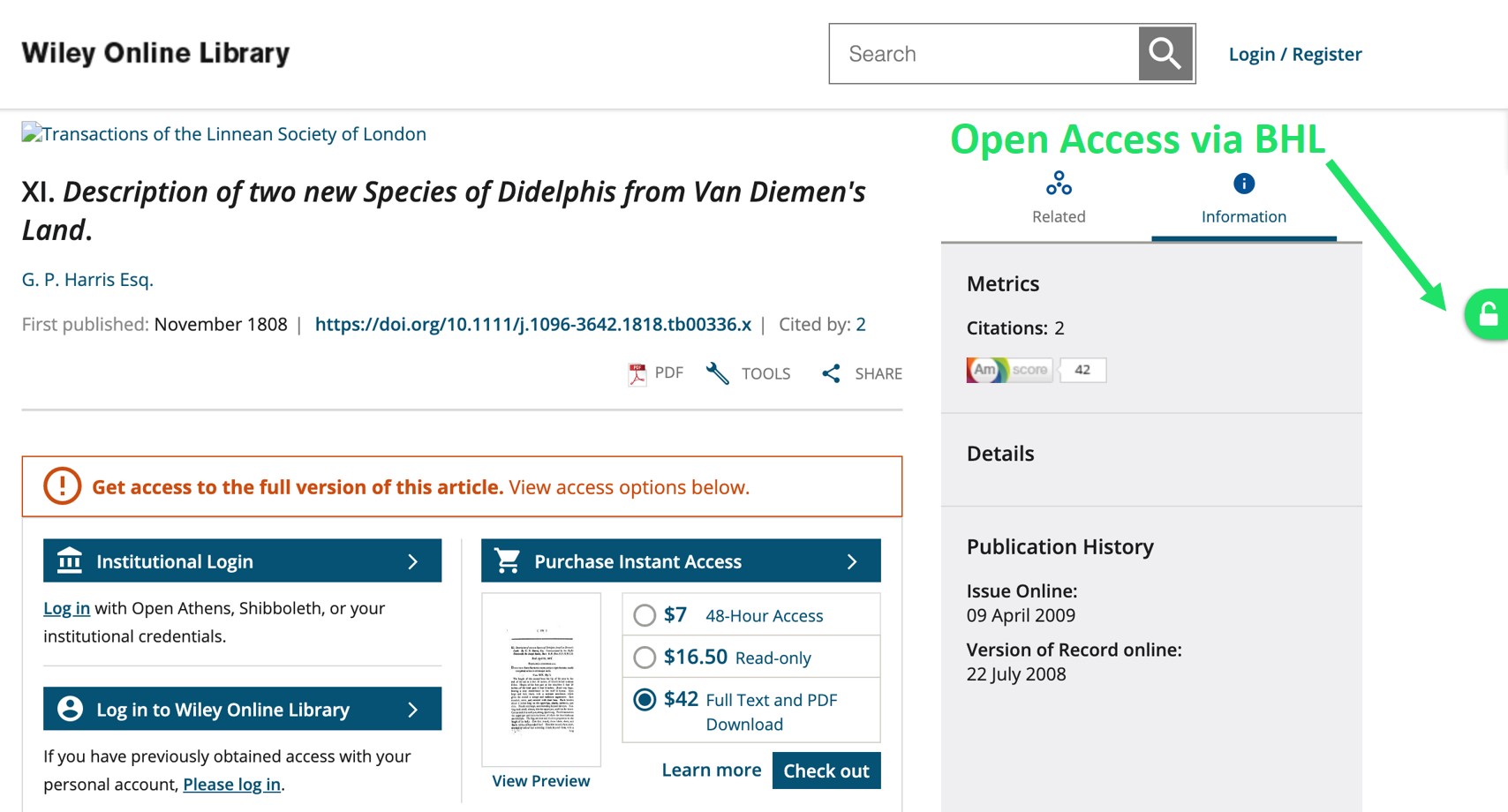
The definitive DOI version of this article is behind a paywall on the Wiley Online website, but it is freely available on the BHL website. With the Unpaywall extension, you can now easily navigate to the free version on BHL.
Now that BHL’s content is discoverable via Unpaywall, anyone directed to the Wiley version via the article’s DOI can discover the free version on BHL (via the Unpaywall extension).
It’s important to note that making BHL discoverable via Unpaywall doesn’t just enhance access to legacy literature such as the Thylacine paper; it also applies to much more recent research. For example, “The generic relationships of the new endemic Australian ant spider genus Notasteron (Araneae, Zodariidae)” was published in The Journal of Arachnology in 2005. This article has the DOI (https://doi.org/10.1636/04-56.1) and is behind a paywall on BioOne. With Unpaywall’s extension in your browser you can now discover the free version hosted by BHL.
How to make even more BHL content discoverable via Unpaywall
43,000 may seem like a large number, but it’s actually only a tiny fraction of the articles freely available on BHL. For the Unpaywall extension to be able to locate all the journal content on BHL, we need to unlock the rest of the journal articles on BHL by 1) adding more article-level metadata, and 2) ensuring that, for every article on BHL that has an existing DOI, we include that DOI in the article-level metadata. That’s our next task…
We would like to thank Unpaywall for providing access to an ever-increasing number of open access scholarly articles (23,943,966 at 14/8/19) and to particularly thank their Lead Developer, Richard Orr, for making it possible for BHL (a square peg) to fit into their open database (a round hole).


Leave a Comment