

Illuminating BHL’s Dark Data: Citizen Scientists and AI Unlock Key Biodiversity Data in GBIF
In the face of climate change and environmental challenges, understanding and documenting Earth’s biodiversity is essential. The Global Biodiversity Information Facility (GBIF) serves as a global repository for biodiversity data, playing a pivotal role in this critical mission of safeguarding our planet’s biodiversity. Species occurrence data sourced from the Biodiversity Heritage Library (BHL) provides insights into species distributions, behaviors, and interactions much deeper into time, offering key species baseline data required to effectively address the climate crisis. Without accurate and comprehensive data in GBIF, our collective ability to track environmental changes and make informed decisions is severely hampered.
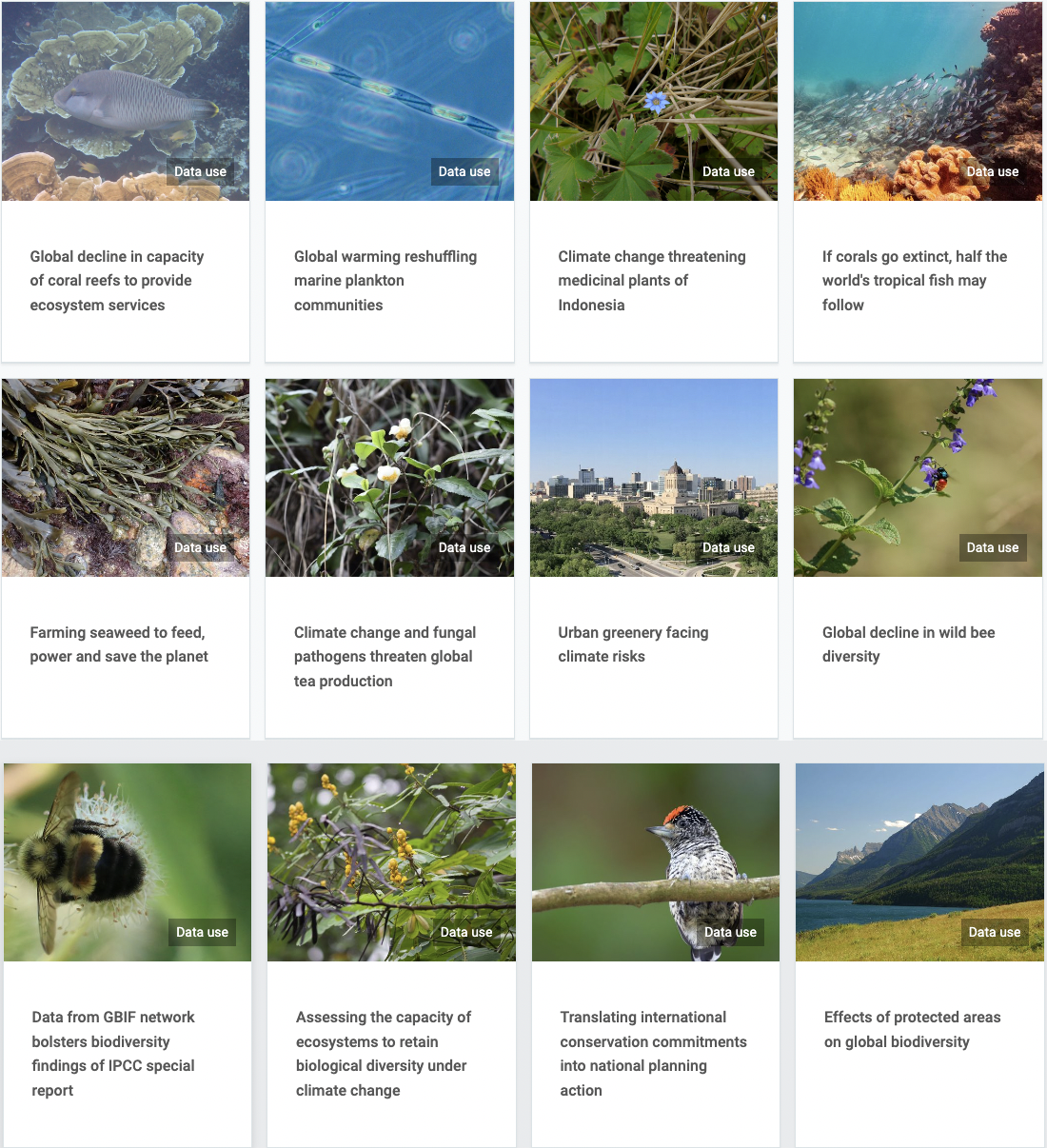
Figure 1: GBIF-mediated data is used extensively in climate science and informs global environmental policy. For more information see: https://www.gbif.org/climate
As a GBIF participant node, BHL is committed to sharing biodiversity data openly, adhering to FAIR (Findable, Accessible, Interoperable, Reusable) and CARE (Collective Benefit, Authority to Control, Responsibility, Ethics) data principles, and collaborating with a global network of biodiversity organizations to bolster and build capacity to strengthen the biodiversity information infrastructure. To honor our commitments, technical staff from BHL are working to establish a scalable data pipeline of occurrence data currently trapped in archival field notes, journals, letters, correspondence, and other primary source materials. The journey has been an arduous one due to poor OCR (optical character recognition) data quality for BHL’s sub-corpus of handwritten materials.

Figure 2: Sample of “dark” handwritten observation data with corresponding unstructured, uncorrected OCR text. From National Museum of Natural History, Pacific Ocean Biological Survey Program, At-sea, 1963-1966, 1968, part 3: July – August 1966.
Technical approaches to building a BHL ETL (Extract, Transform, and Load) data pipeline of species occurrence data from BHL’s field notes include machine learning, artificial intelligence (AI), and data extraction through innovative transcription projects like DigiVol, the crowdsourcing citizen science platform collaboration between the Australian Museum and the Atlas of Living Australia.
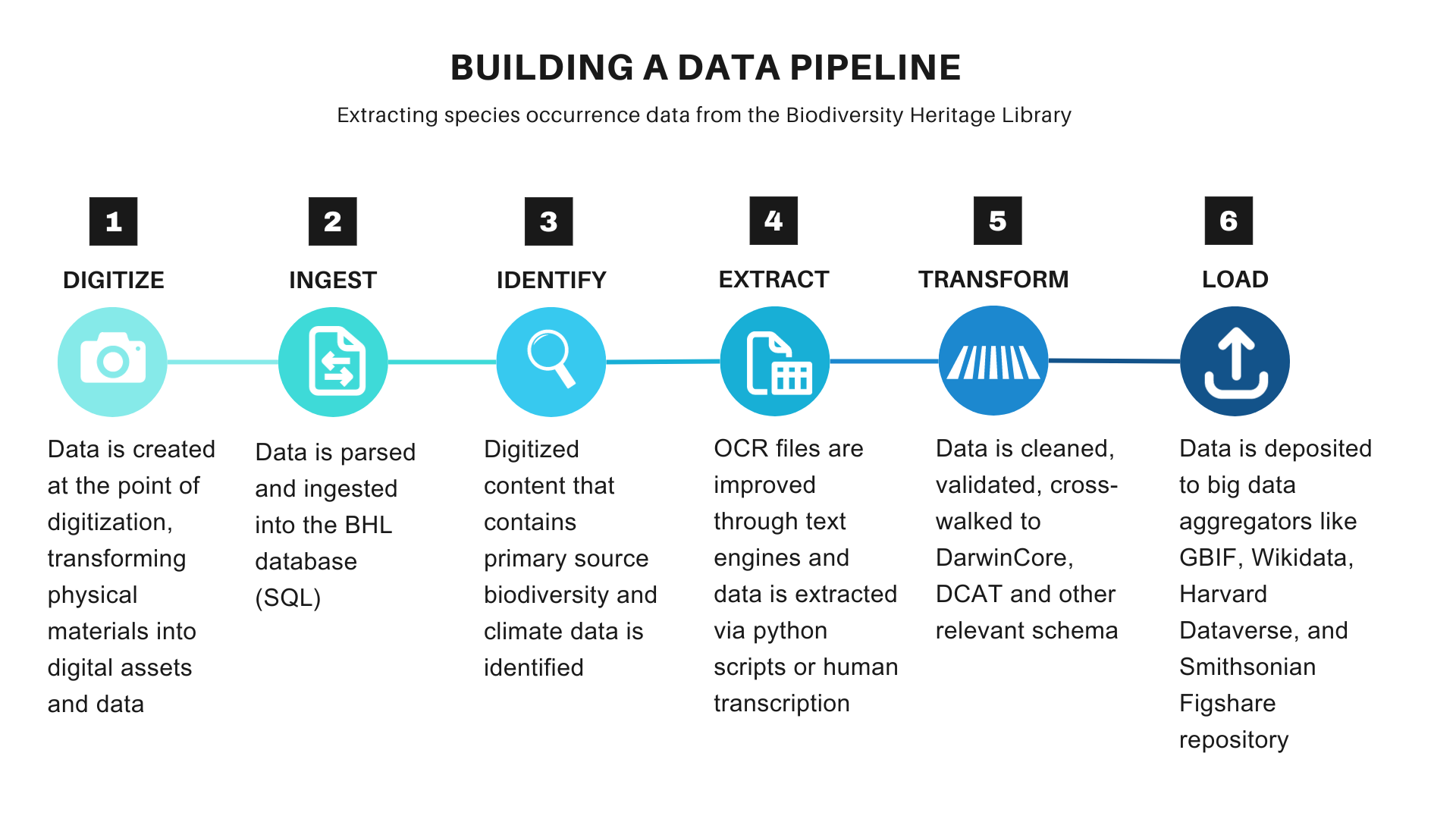
Figure 3: Learn more about how BHL is building a new data pipeline from the recent talk given at TDWG 2023 entitled Unearthing the Past for a Sustainable Future: Extracting and transforming data in the Biodiversity Heritage Library for climate action; abstract; recording.
Now underway, is a global effort to convert centuries of biodiversity knowledge into accessible and actionable data, utilizing advanced AI and technical approaches. BHL Partners now have a stake in supporting international conservation policy aimed at safeguarding Earth’s biodiversity through greater data integration with the global biodiversity data infrastructure.
The Journals of William Brewster
The ornithological papers of William Brewster (1851-1919), held in the Ernst Mayr Library and Archives of the Museum of Comparative Zoology (MCZ) at Harvard University, are a rich source of historical species occurrence data and an ideal use case for building a BHL ETL data pipeline. Brewster’s field notes, journals, diaries, and correspondence comprise over 60,000 pages replete with detailed bird observations spanning 54 years (1865-1919). These records augment and extend his collection of over 40,000 bird specimens, bequeathed by Brewster to the MCZ and considered “one of the largest private collections ever made in this country [United States], and in some respects … by far the most valuable” (Henshaw, 1920). Thanks to a number of projects facilitated by the Ernst Mayr Library over the years, Brewster’s journals have been digitized and later transcribed using DigiVol.
Figure 4 below shows one example of Brewster’s extensive species lists. Brewster fastidiously recorded all essential elements of a species occurrence record and often more such as habitat information and detailed behavioral descriptions. The complexity of this example, featuring Brewster’s unique formatting, use of ornithological symbols, and tiny, crowded handwriting, highlights the value of crowdsourced human transcription by a team of enthusiastic, dedicated volunteers.
Figure 5 shows a portion of the transcription of this species list, produced in DigiVol by one of our long-time transcribers.
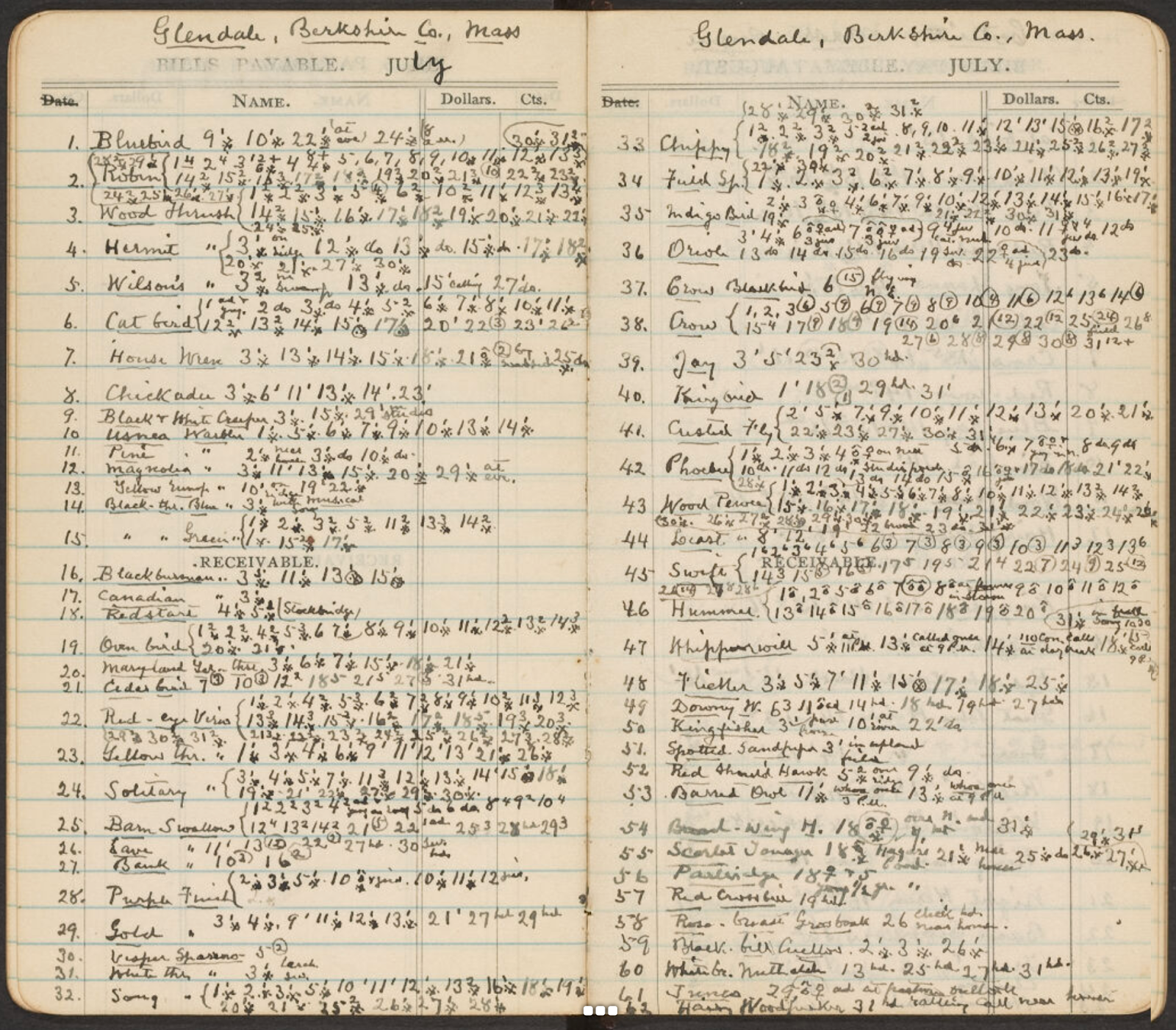
Figure 4. Brewster’s bird observations for July from his 1915 Diary.

Figure 5. A portion of the transcript of Brewster’s July, 1915 species list.
Extracting Data via Citizen Scientists and DigiVol
DigiVol, first developed in 2011 to crowdsource the transcription of specimen labels, enables institutions around the world to engage volunteers to extract data of various types, such as text, species identifications, and species traits from images. Each institution is able to upload images and manage their crowdsourcing project through the DigiVol platform. Through a combination of gamification and engagement tools such as a user forum and secure, private emails, institutions can build volunteer skills, a sense of community, and commitment.
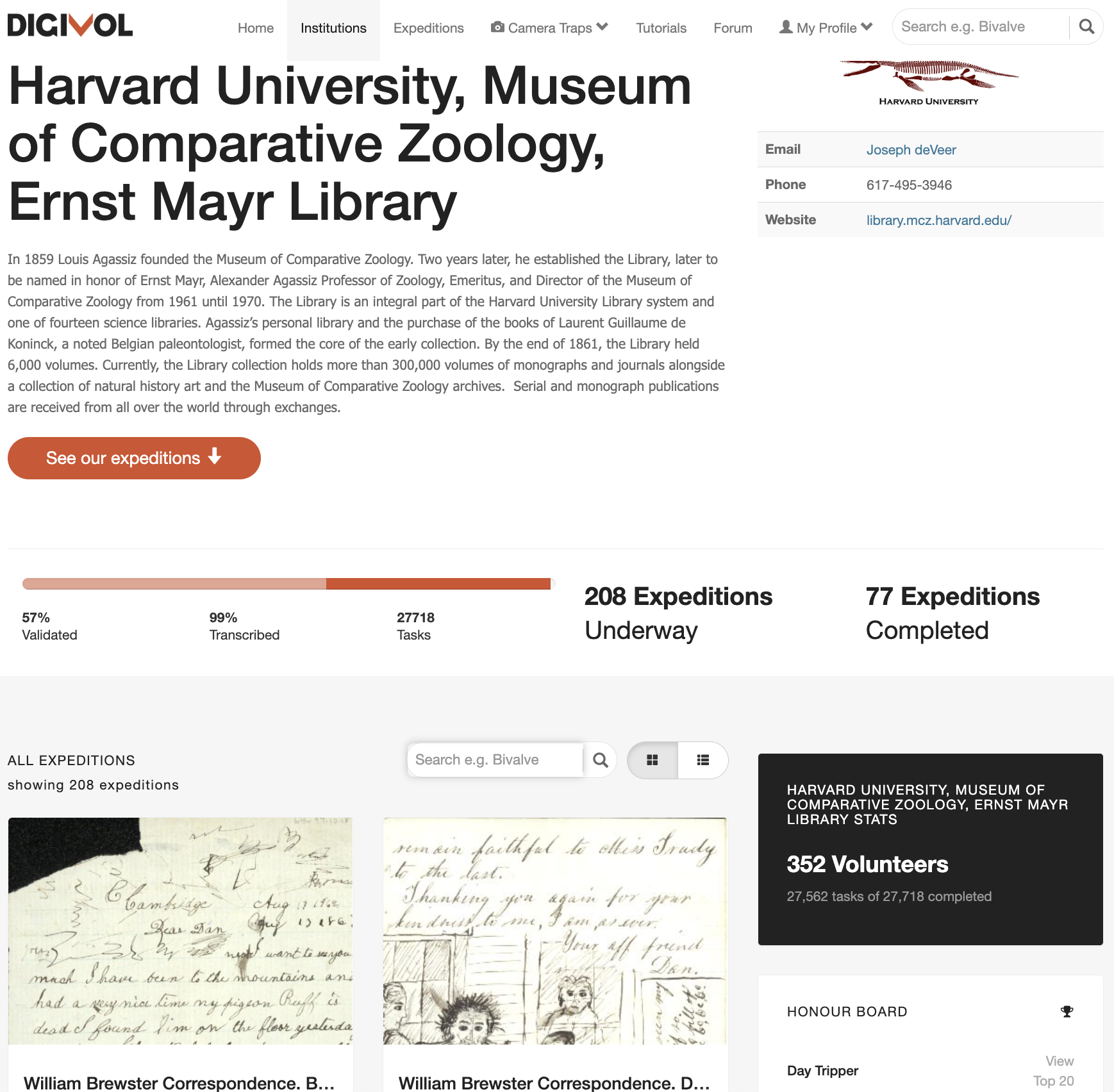
Figure 6: The DigiVol dashboard for the Harvard Museum of Comparative Zoology, Ernst Mayr Library.
Volunteers on the website can contribute any time of day – 24/7, 365 days a year. They can choose from a broad array of “virtual expeditions” on DigiVol, from identifying animals in camera traps located in the Australian “bush” to transcribing specimen labels and field notes from locations around the world.
The DigiVol platform has seen more than 14,000 volunteers contribute 155 equivalent work years (7 hour days, 261 days a year) to the digitisation of over 6 million tasks at an estimated equivalent value of A$12 million.
In terms of the William Brewster project, 352 volunteers have transcribed over 27,000 pages of diaries and field notes, at an average 23 minutes per page. This contribution amounts to more than 5.8 work years at an equivalent cost of A$462,000.
Publishing Data to GBIF
The final output of these recent data pipeline investigations was the deposit of 1,853 species occurrence records at GBIF from the Journals of William Brewster. The data deposit comprises valuable biodiversity records extracted through transcription efforts on DigiVol, transformed into DarwinCore, and subsequently published on GBIF. The species occurrence records span diverse geographical locations, primarily focusing on New England but extending to other regions of the United States, the Caribbean, and Europe. Brewster’s meticulous observations, encompassing species observation, behavioral data, and environmental conditions offer a rich historical perspective on biodiversity dating back over a century.
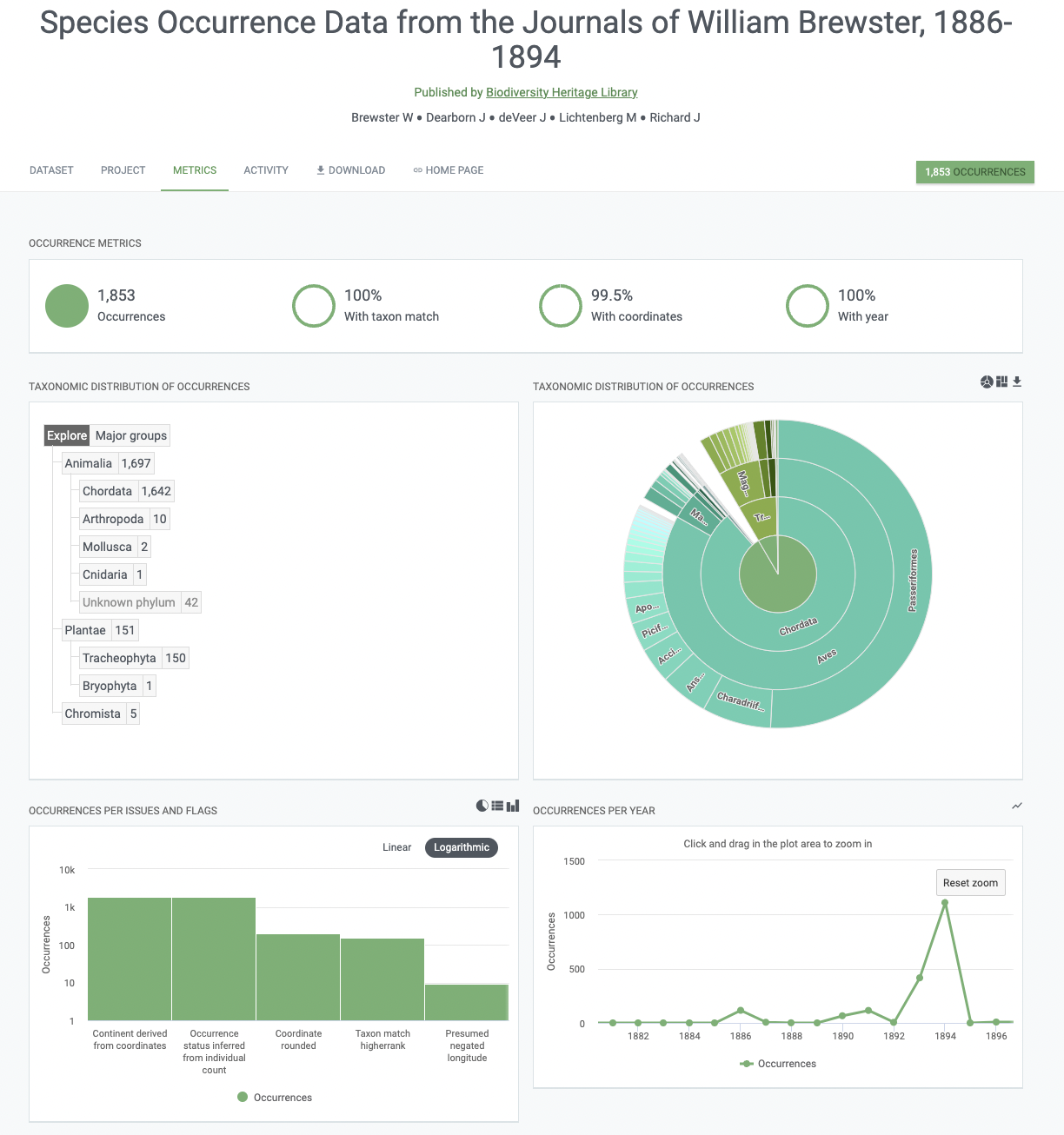
Figure 7: Species Occurrence Data from the Journals of William Brewster are now available on GBIF. Additional data deposits are planned in 2024. Data deposit: https://doi.org/10.15468/q45atb
This deposit of historic biodiversity data demonstrates how valuable BHL’s collection is to global biodata infrastructure, as it plays a crucial role in establishing species base lines, informing climate change studies, tracking key environmental indicators, and contributing to the development of global biodiversity monitoring platforms.
Having the data available in BHL, even as transcribed text is one thing, but it is the human resources to review and reconcile the data that is really required to facilitate the flow of historic biodiversity data into today’s bioinformatics ecosystems. To all the humans involved in this species data project, from the initial observation and recording, to the preservation, digitization, transcription, data extraction and reconciliation, machine-learning, and creation of vital ETL data pipelines, we thank you.
Related Works
Biodiversity Heritage Library Open Data Collection. (2022, November). Smithsonian Figshare.
Crowley, B., Dearborn, J., Funkhouser, C., Kalfatovic, M., Merriman, K., Iggulden, D., Trei, K., & Herrmann, E. (2023, October). Safeguarding Access to 500 Years of Biodiversity Data: Sustainability Planning for the Biodiversity Heritage Library [TDWG2023]. Biodiversity Information Standards, Hobart, Tasmania, Australia.
Data Flows Diagram. (2023, March). BHL Technical Team (BHL-TECH) Biodiversity Heritage Library.
Dearborn, JJ (2023, April). Unifying Biodiversity Knowledge for Life on a Sustainable Planet. Biodiversity Heritage Library. https://bhl.pubpub.org/
deVeer, J. (2021, February 24). Making the Best of Difficult Times: Accelerating the Transcription of William Brewster’s Writings During the COVID-19 Pandemic. Biodiversity Heritage Library.https://blog.biodiversitylibrary.org/2021/02/accelerating-transcription-brewster-covid19.html
deVeer, J. and Rinaldo, C. (2021, February 23). The Life and Work of Robert Alexander Gilbert: Empowering New Insights through Digitization and Transcription of Archival Materials. Biodiversity Heritage Library. https://blog.biodiversitylibrary.org/2021/02/life-work-robert-gilbert.html
Henshaw, Henry W. 1920. In Memoriam: William Brewster, Born July 5, 1851 – Died July 11, 1919. The Auk 37, 1 (1920), 1–23. https://doi.org/10.2307/4072953
Lichtenberg, M. (n.d.). BHL Data Model. BHL Github Repository. https://github.com/gbhl/bhl-us/tree/master/Documentation/DataModel
Mika, K. and Dearborn, J. (2022). [poster] Extracting expedition log data found in the Biodiversity Heritage Library. Through the door and through the web: releasing the power of natural history collections onsite and online, June 5, 2023. Edinburgh, Scotland, United Kingdom: Society for the Preservation of Natural History Collections (SPNHC). https://doi.org/10.5281/zenodo.6593457.
Richard, J. (2022, December 20). OCR Improvements: An Early Analysis. Biodiversity Heritage Library. https://blog.biodiversitylibrary.org/2022/07/ocr-improvements-early-analysis.html
Rinaldo, C. (2021, February 22). Nature Conservation and William Brewster: Insights From a Lifetime of Scientific Observations. Biodiversity Heritage Library. https://blog.biodiversitylibrary.org/2021/02/william-brewster-post-one
Trizna, M., & Dearborn, J. (2023, June). AI models are getting better and better at reading handwriting, but how can we find handwritten text to begin with? [poster]. 7th Annual Digital Data Conference, Leveraging Digital Data for Conservation, Ecology, Systematics, and Novel Biodiversity Research, Tempe, Arizona, United States of America. https://doi.org/10.25573/data.23523495.v1


Leave a Comment